The RSM Framework
Methods derived from Soft RL, GFlowNets, and optimal control all reduce to the same underlying score-matching objective. Their primary differences arise from three coupled design choices:
Common RSM Loss:
\(\mathcal{L}(\theta) = \mathbb{E}_{t_i, x_{t_i}}\!\Big[ C_1(t_i)\| s^\theta_{t_i} - (s^{\mathrm{ref}}_{t_i} + \Psi_{t_i})\|^2 + C_2(t_i)\| s^\theta_{t_i} - s^{\theta^\dagger}_{t_i}\|^2 \Big]\)
Methods differ only in how $\Psi_{t_i}$ (value guidance), $C_1(t_i)$ (temporal weight), $C_2(t_i)$ (trust region) are constructed.
🎯
Estimator Design
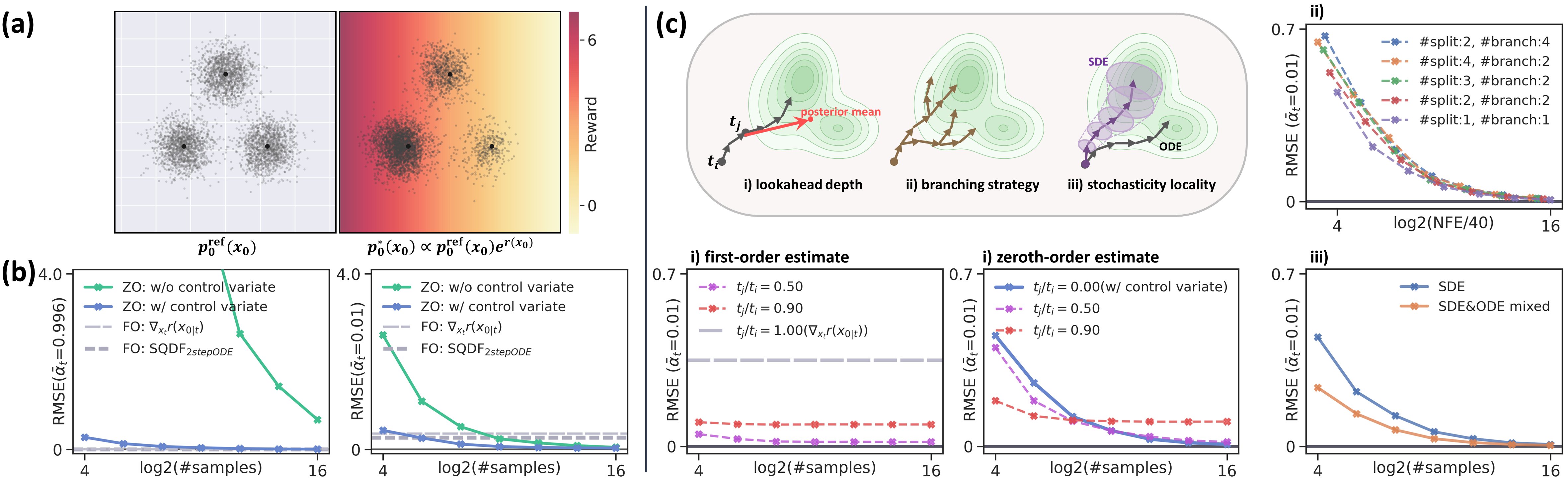
First and zeroth-order estimators. Lookahead depth, branching, stochasticity localization. Governs bias–variance–compute tradeoff.
⚖️
Temporal Weighting
$\gamma(t_i)$ and Normalized Influence Metric $h(t_i)$ control per-timestep optimization strength.
🛡️
Trust-Region
$C_2(t_i)$ and clipping determine how much of each update survives regularization.
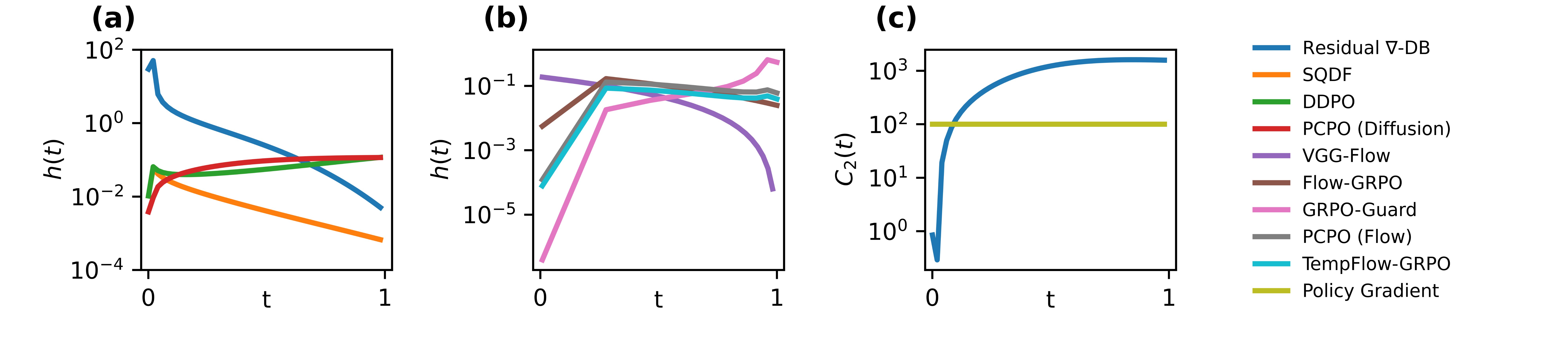
Temporal Optimization Strength $h(t)$. (a, b) Successful first-order methods suppress value guidance at low-SNR timesteps, whereas improved zeroth-order methods suppress it at high-SNR timesteps. (a: Diffusion. b: Flow matching). (c) Residual ∇-DB enforces stronger trust-region constraints for low-SNR timesteps. Policy Gradient’s $C_2(t)$ is depicted for constant $r(x_0) = 1$ and $\alpha = 10^-2$